



Linux下core文件產生的一些注意問題
前面轉載了一篇文章關于core文件的產生和調試使用的設置,但在使用有一些需要注意的問題,如 在什么情況 才會正確地產生core文件。
列出一些常見問題:
一,如何使用core文件
1. 使用core文件
在core文件所在目錄下鍵入:
gdb -c core
它會啟動GNU的調試器,來調試core文件,并且會顯示生成此core文件的程序名,中止此程序的信號等等。
如果你已經知道是由什么程序生成此core文件的,比如MyServer崩潰了生成core.12345,那么用此指令調試:
gdb -c core MyServer
以下怎么辦就該去學習gdb的使用了
2. 一個小方法來測試產生core文件
直接輸入指令:kill -s SIGSEGV $$
二,程序產生core的原因
造成程序coredump的原因很多,這里根據以往的經驗總結一下:
1 內存訪問越界
a) 由于使用錯誤的下標,導致數組訪問越界
b) 搜索字符串時,依靠字符串結束符來判斷字符串是否結束,但是字符串沒有正常的使用結束符
c) 使用strcpy, strcat, sprintf, strcmp, strcasecmp等字符串操作函數,將目標字符串讀/寫爆。應該使用strncpy, strlcpy, strncat, strlcat, snprintf, strncmp, strncasecmp等函數防止讀寫越界。
2 多線程程序使用了線程不安全的函數。
應該使用下面這些可重入的函數,尤其注意紅色標示出來的函數,它們很容易被用錯:
asctime_r(3c) gethostbyname_r(3n) getservbyname_r(3n) ctermid_r(3s) gethostent_r(3n) getservbyport_r(3n) ctime_r(3c) getlogin_r(3c) getservent_r(3n) fgetgrent_r(3c) getnetbyaddr_r(3n) getspent_r(3c) fgetpwent_r(3c) getnetbyname_r(3n) getspnam_r(3c) fgetspent_r(3c) getnetent_r(3n) gmtime_r(3c) gamma_r(3m) getnetgrent_r(3n) lgamma_r(3m) getauclassent_r(3) getprotobyname_r(3n) localtime_r(3c) getauclassnam_r(3) etprotobynumber_r(3n) nis_sperror_r(3n) getauevent_r(3) getprotoent_r(3n) rand_r(3c) getauevnam_r(3) getpwent_r(3c) readdir_r(3c) getauevnum_r(3) getpwnam_r(3c) strtok_r(3c) getgrent_r(3c) getpwuid_r(3c) tmpnam_r(3s) getgrgid_r(3c) getrpcbyname_r(3n) ttyname_r(3c) getgrnam_r(3c) getrpcbynumber_r(3n) gethostbyaddr_r(3n) getrpcent_r(3n)
3 多線程讀寫的數據未加鎖保護。
對于會被多個線程同時訪問的全局數據,應該注意加鎖保護,否則很容易造成core dump
4 非法指針
a) 使用空指針
b) 隨意使用指針轉換。一個指向一段內存的指針,除非確定這段內存原先就分配為某種結構或類型,或者這種結構或類型的數組,否則不要將它轉換為這種結構或類型的指針,而應該將這段內存拷貝到一個這種結構或類型中,再訪問這個結構或類型。這是因為如果這段內存的開始地址不是按照這種結構或類型對齊的,那么訪問它時就很容易因為bus error而core dump.
5 堆棧溢出
不要使用大的局部變量(因為局部變量都分配在棧上),這樣容易造成堆棧溢出,破壞系統的棧和堆結構,導致出現莫名其妙的錯誤。
三,注意的問題
在Linux下要保證程序崩潰時生成Coredump要注意這些問題:
一、要保證存放Coredump的目錄存在且進程對該目錄有寫權限。存放Coredump的目錄即進程的當前目錄,一般就是當初發出命令啟動該進程時所在的目錄。但如果是通過腳本啟動,則腳本可能會修改當前目錄,這時進程真正的當前目錄就會與當初執行腳本所在目錄不同。這時可以查看”/proc/<進程pid>/cwd“符號鏈接的目標來確定進程真正的當前目錄地址。通過系統服務啟動的進程也可通過這一方法查看。
二、若程序調用了seteuid()/setegid()改變了進程的有效用戶或組,則在默認情況下系統不會為這些進程生成Coredump。很多服務程序都會調用seteuid(),如MySQL,不論你用什么用戶運行mysqld_safe啟動MySQL,mysqld進行的有效用戶始終是msyql用戶。如果你當初是以用戶A運行了某個程序,但在ps里看到的這個程序的用戶卻是B的話,那么這些進程就是調用了seteuid了。為了能夠讓這些進程生成core dump,需要將/proc/sys/fs /suid_dumpable文件的內容改為1(一般默認是0)。
三、要設置足夠大的Core文件大小限制了。程序崩潰時生成的Core文件大小即為程序運行時占用的內存大小。但程序崩潰時的行為不可按平常時的行為來估計,比如緩沖區溢出等錯誤可能導致堆棧被破壞,因此經常會出現某個變量的值被修改成亂七八糟的,然后程序用這個大小去申請內存就可能導致程序比平常時多占用很多內存。因此無論程序正常運行時占用的內存多么少,要保證生成Core文件還是將大小限制設為unlimited為好。
在shell里使用命令:ulimit -c unlimited,這樣進行修改只是對本次會話有效,是臨時的,如果想讓修改永久生效,則需要修改配置文件,如 .bash_profile、/etc/profile或/etc/security/limits.conf
如下:
[root@otctest ~]# vim /etc/profile
結果如圖:
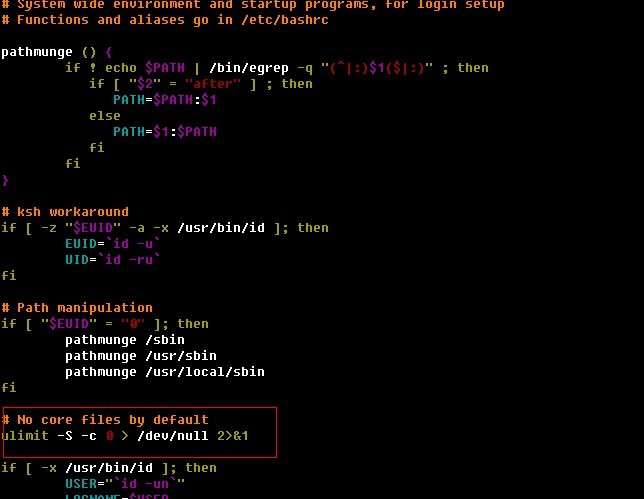
把紅框里的行注釋,并新加入一行:
ulimit -c unlimited
保存,退出即可。
四,產生core文件的時機
當我們的程序崩潰時,內核有可能把該程序當前內存映射到core文件里,方便程序員找到程序出現問題的地方。最常出現的,幾乎所有C程序員都出現過的錯誤就是“段錯誤”了。也是最難查出問題原因的一個錯誤。下面我們就針對“段錯誤”來分析core文件的產生、以及我們如何利用core文件找到出現崩潰的地方。
何謂core文件
當一個程序崩潰時,在進程當前工作目錄的core文件中復制了該進程的存儲圖像。core文件僅僅是一個內存映象(同時加上調試信息),主要是用來調試的。
當程序接收到以下UNIX信號會產生core文件:
名字
說明
ANSI C POSIX.1
SVR4 4.3+BSD
缺省動作
SIGABRT
異常終止(abort)
. .
. .
終止w/core
SIGBUS
硬件故障
.
. .
終止w/core
SIGEMT
硬件故障
. .
終止w/core
SIGFPE
算術異常
. .
. .
終止w/core
SIGILL
非法硬件指令
. .
. .
終止w/core
SIGIOT
硬件故障
. .
終止w/core
SIGQUIT
終端退出符
.
. .
終止w/core
SIGSEGV
無效存儲訪問
. .
. .
終止w/core
SIGSYS
無效系統調用
. .
終止w/core
SIGTRAP
硬件故障
. .
終止w/core
SIGXCPU
超過CPU限制(setrlimit)
. .
終止w/core
SIGXFSZ
超過文件長度限制(setrlimit)
. .
終止w/core
在系統默認動作列,“終止w/core”表示在進程當前工作目錄的core文件中復制了該進程的存儲圖像(該文件名為core,由此可以看出這種功能很久之前就是UNIX功能的一部分)。大多數UNIX調試程序都使用core文件以檢查進程在終止時的狀態。
core文件的產生不是POSIX.1所屬部分,而是很多UNIX版本的實現特征。UNIX第6版沒有檢查條件(a)和(b),并且其源代碼中包含如下說明:“如果你正在找尋保護信號,那么當設置-用戶-ID命令執行時,將可能產生大量的這種信號”。4.3 + BSD產生名為core.prog的文件,其中prog是被執行的程序名的前1 6個字符。它對core文件給予了某種標識,所以是一種改進特征。
表中“硬件故障”對應于實現定義的硬件故障。這些名字中有很多取自UNIX早先在DP-11上的實現。請查看你所使用的系統的手冊,以確切地確定這些信號對應于哪些錯誤類型。
下面比較詳細地說明這些信號。
• SIGABRT 調用abort函數時產生此信號。進程異常終止。
• SIGBUS 指示一個實現定義的硬件故障。
• SIGEMT 指示一個實現定義的硬件故障。
EMT這一名字來自PDP-11的emulator trap 指令。
• SIGFPE 此信號表示一個算術運算異常,例如除以0,浮點溢出等。
• SIGILL 此信號指示進程已執行一條非法硬件指令。
4.3BSD由abort函數產生此信號。SIGABRT現在被用于此。
• SIGIOT 這指示一個實現定義的硬件故障。
IOT這個名字來自于PDP-11對于輸入/輸出TRAP(input/output TRAP)指令的縮寫。系統V的早期版本,由abort函數產生此信號。SIGABRT現在被用于此。
• SIGQUIT 當用戶在終端上按退出鍵(一般采用Ctrl-/)時,產生此信號,并送至前臺進
程組中的所有進程。此信號不僅終止前臺進程組(如SIGINT所做的那樣),同時產生一個core文件。
• SIGSEGV 指示進程進行了一次無效的存儲訪問。
名字SEGV表示“段違例(segmentation violation)”。
• SIGSYS 指示一個無效的系統調用。由于某種未知原因,進程執行了一條系統調用指令,
但其指示系統調用類型的參數卻是無效的。
• SIGTRAP 指示一個實現定義的硬件故障。
此信號名來自于PDP-11的TRAP指令。
• SIGXCPU SVR4和4.3+BSD支持資源限制的概念。如果進程超過了其軟C P U時間限制,則產生此信號。
• SIGXFSZ 如果進程超過了其軟文件長度限制,則SVR4和4.3+BSD產生此信號。
摘自《UNIX環境高級編程》第10章 信號。
使用core文件調試程序
看下面的例子:
/*core_dump_test.c*/
#include <stdio.h>
const char *str = "test";
void core_test(){
str[1] = 'T';
}
int main(){
core_test();
return 0;
}
編譯:
gcc –g core_dump_test.c -o core_dump_test
如果需要調試程序的話,使用gcc編譯時加上-g選項,這樣調試core文件的時候比較容易找到錯誤的地方。
執行:
./core_dump_test
段錯誤
運行core_dump_test程序出現了“段錯誤”,但沒有產生core文件。這是因為系統默認core文件的大小為0,所以沒有創建。可以用ulimit命令查看和修改core文件的大小。
ulimit -c 0
ulimit -c 1000
ulimit -c 1000
-c 指定修改core文件的大小,1000指定了core文件大小。也可以對core文件的大小不做限制,如:
ulimit -c unlimited
ulimit -c unlimited
如果想讓修改永久生效,則需要修改配置文件,如 .bash_profile、/etc/profile或/etc/security/limits.conf。
再次執行:
./core_dump_test
段錯誤 (core dumped)
ls core.*
core.6133
可以看到已經創建了一個core.6133的文件.6133是core_dump_test程序運行的進程ID。
調式core文件
core文件是個二進制文件,需要用相應的工具來分析程序崩潰時的內存映像。
file core.6133
core.6133: ELF 32-bit LSB core file Intel 80386, version 1 (SYSV), SVR4-style, from 'core_dump_test'
在Linux下可以用GDB來調試core文件。
gdb core_dump_test core.6133
GNU gdb Red Hat Linux (5.3post-0.20021129.18rh)
Copyright 2003 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i386-redhat-linux-gnu"...
Core was generated by `./core_dump_test'.
Program terminated with signal 11, Segmentation fault.
Reading symbols from /lib/tls/libc.so.6...done.
Loaded symbols for /lib/tls/libc.so.6
Reading symbols from /lib/ld-linux.so.2...done.
Loaded symbols for /lib/ld-linux.so.2
#0 0x080482fd in core_test () at core_dump_test.c:7
7 str[1] = 'T';
(gdb) where
#0 0x080482fd in core_test () at core_dump_test.c:7
#1 0x08048317 in main () at core_dump_test.c:12
#2 0x42015574 in __libc_start_main () from /lib/tls/libc.so.6
GDB中鍵入where,就會看到程序崩潰時堆棧信息(當前函數之前的所有已調用函數的列表(包括當前函數),gdb只顯示最近幾個),我們很容易找到我們的程序在最后崩潰的時候調用了core_dump_test.c 第7行的代碼,導致程序崩潰。注意:在編譯程序的時候要加入選項-g。您也可以試試其他命令, 如 fram、list等。更詳細的用法,請查閱GDB文檔。
core文件創建在什么位置
在進程當前工作目錄的下創建。通常與程序在相同的路徑下。但如果程序中調用了chdir函數,則有可能改變了當前工作目錄。這時core文件創建在chdir指定的路徑下。有好多程序崩潰了,我們卻找不到core文件放在什么位置。和chdir函數就有關系。當然程序崩潰了不一定都產生core文件。
什么時候不產生core文件
在下列條件下不產生core文件:
( a )進程是設置-用戶-ID,而且當前用戶并非程序文件的所有者;
( b )進程是設置-組-ID,而且當前用戶并非該程序文件的組所有者;
( c )用戶沒有寫當前工作目錄的許可權;
( d )文件太大。core文件的許可權(假定該文件在此之前并不存在)通常是用戶讀/寫,組讀和其他讀。
利用GDB調試core文件,當遇到程序崩潰時我們不再束手無策。
文章出處:http://blog.csdn.net/fengxinze/article/details/6800175
RFID管理系統集成商 RFID中間件 條碼系統中間層 物聯網軟件集成